目录
1、PyTorch框架介绍
2、安装Pytorch
2.1、CPU版本的安装命令:
2.2、GPU版本的安装命令:
2.2.1、安装CUDA
3、基本使用方法
4、Pytorch中的自动求导机制
4.1、例子:
4.2、做一个线性回归试试水
4.2.1、CPU训练版本
4.2.1、GPU训练版本
5、常见tensor格式
6、Pytorch中非常强大的模块:hub模块
6.1、Pytorch hub模块官网:
6.2、Pytorch hub 的github 站点:
6.3、演示
1、PyTorch框架介绍
Torch其实跟Tensorflow中的Tensor是一个意思,当做是能在GPU中计算的矩阵就可以啦。
意思就是现在我们有了一批数据,无论你是图像数据还是文本数据,我们都需要把数据转化成一个矩阵,接下来在建模过程当中,我们就是要对这些数据做各种各样的变换,这一些流程做完之后,得到我们想要达到的结果。PYtorch其实做了这样一些事情,他把我们所有矩阵需要计算的东西,统统的传入到GPU当中,因为GPU当中做矩阵运算比较快,GPU当中帮我们实现了所有的计算功能,整体的一个计算,从前向传播到反向传播,有可能涉及到的非常复杂的计算,这些计算统统框架都帮我们实现了,我们要去做的就是去设计整个的网络流程,整个的架构就可以了,所以说深度学习框架说白了就是一个计算的工具,帮我们实现由前到后整体的计算过程。
2、安装Pytorch
官网:PyTorch
使用pip的安装方法比较简单
2.1、CPU版本的安装命令:
pip3 install torch torchvision torchaudio

2.2、GPU版本的安装命令:
pip3 install torch==1.9.1+cu102 torchvision==0.10.1+cu102 torchaudio===0.9.1 -f https://download.pytorch.org/whl/torch_stable.html
GPU版本需要选择你的CUDA版本;(所以先按照下边的步骤安装CUDA,注意版本对应)

(最好安装GPU版本,也就是说我们有显卡,有显卡我们在训练模型的时候是非常快速的)
也可以将上述命令复制到Anaconda Prompt中,执行命令,他会先帮我们下载然后进行安装。
2.2.1、安装CUDA
CUDA官网:
https://developer.nvidia.com/zh-cn
进入安装页面:
https://developer.nvidia.com/cuda-downloads?target_os=Windows&target_arch=x86_64

选择你要安装的系统是windows还是linux,然后选择64位的,选择安装版本,然后把exe程序给下载下来;下载下来之后.exe程序你自己安装一下就行了。者那样就是安装一个CUDA,很简单。
3、基本使用方法
建议先大致熟悉一下基本的操作,不需要花太多时间,后续融入到实战项目中去边看边练。以下所有演示都是在jupyter notebook中。学框架不要一步步的去看基本操作,直接去看实际的例子我们一步步怎么去走就可以了,边看边查。
(1)创造一个矩阵

它的格式是一个tensor,是一个张量,把他当做是一个矩阵就行了,这个矩阵里边几维的都行,一维的是一个向量,二维的是一个矩阵,还有多维的,不管他是一个几维的我统一把他叫做一个tensor,他在我们深度学习当中是一个最基本的单元,是框架的底层了。你要用PyTorch框架,需要把数据都转化成tensor的格式,tensor的格式才是他底层所支持的一个格式。框架当中基本的要求所有的格式所有的计算都是对tensor所执行的,所以说每一次当我调torch API当中,得到的结果都是tensor格式。
(2)创造一个矩阵(随机的5行3列)

(2)创造一个矩阵(全0的矩阵)
 跟Numpy当中很相似,只不过在Numpy当中得到的是ndarray,在这里得到的是tensor格式。
跟Numpy当中很相似,只不过在Numpy当中得到的是ndarray,在这里得到的是tensor格式。
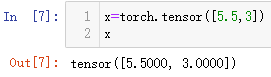
(3)直接传入数据
(4)构建一个同样大小的矩阵

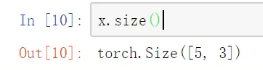
(5)展示矩阵大小(表示当前的矩阵是几行几列的,维度全部计算出来了,类似于.shape)
(6)矩阵加法

(7)索引(跟python和numpy当中都是一模一样的,冒号:表示取所有)

(8)改变矩阵维度view操作(类似于.reshape操作)

将4x4的矩阵拉成一个向量,拉成一行;view就是把他reshape成一个新的维度。-1表示自动去做计算,第二个维度有8个元素,那么第一个维度就是自动计算16/8=2。
(9)与Numpy的协同操作(互相转换)
我们通常读进来的数据,不论你使用的是opencv还是其他的工具包,第一步都是说把数据读进来,读进来的数据一般都是ndarray的格式,该格式不能和tensor的格式交互计算,所以需要把tensor格式转化成Numpy中的ndarray格式,可以进行直接转换。
(9.1)把tensor格式直接转化成numpy中的ndarray格式。

(9.2)把numpy中的ndarray格式转换成tensor格式。

4、Pytorch中的自动求导机制
在神经网络的反向传播中,我们要对每一个参数进行求导,逐层的进行求导,并且这个w他不是一个数,他是一个矩阵,对这些矩阵进行求导时,难度就比较大,我们用深度学习框架最核心的一点是能帮我们把反向传播全部计算好。我们把时间花在怎么样去设计网络,怎么样去构建网络模型。


4.1、例子:

上述例子自动求导代码;

PyTorch他跟其他框架是不一样的,在做反向传播的时候,如果你不对这个梯度进行一个清0的操作,他每一次会把之前的累加在一起,注意他是做了一个累加的操作。如果你不清0,他默认梯度是累加的;
Q1:在实际的训练模型的过程当中,我每次计算一个梯度,我需要对它做一个累加吗?
A1:一般情况下不需要做一个累加。
如何把梯度先做一个清0,再进行计算,再更新参数,是有一个步骤的?
4.2、做一个线性回归试试水
4.2.1、CPU训练版本
第一步:准备数据x和y

第二步:构建模型


第三步:指定参数和损失函数

第四步:开始训练模型

第五步:模型测试预测结果

第六步:模型的保存与读取

下面是CPU训练版本的代码段:
import torch
import torch.nn as nn#nn模块就是torch.nn模块下有很多丰富的功能我们都可以去用#准备(数据)
#构造一组输入数据X和其对应的标签y
import numpy as np
x_values=[i for i in range(11)]
x_train=np.array(x_values,dtype=np.float32)#x是ndarray的格式
x_train=x_train.reshape(-1,1)#把数据转化成矩阵的格式
x_train.shapey_values=[2*i + 1 for i in x_values]#y=2x+1
y_train=np.array(y_values,dtype=np.float32)
y_train=y_train.reshape(-1,1)
y_train.shape#准备模型
"""
有了x和y之后,构建线性回归模型,让模型学习一下这个w和b分别是多少就可以了。
无论构造一个多么复杂的类型,我都先把这个类构造出来(然后继承一下nn模块),nn模块下有一个Module模块
(Module模块的意思就是里边很多的东西都给我们实现好了,咱直接继承这个里边的,
相当于下边我只需要去写我这个线性回归模型用哪个层就得了,其他的事统统给他省略掉(人家都已经做好了我直接继承过来就得了))
"""
class LinearRegressionModel(nn.Module):def __init__(self,input_dim,output_dim):super(LinearRegressionModel,self).__init__()#由于类的继承导致可能覆盖同名的构造方法,导致只能使用子类的构造,#而无法调用父类的构造方法。但其实可以使用super方法解决这个问题。 self.linear=nn.Linear(input_dim,output_dim)#这里直接使用全连接层(指定参数表示输入数据的维度、输出数据的维度)'''在构造函数里边只需要去写你用到了哪些层,(线性回归无非就是你给我x和y,我训练出w和b,使得wx+b跟y的值越接近越好,这不就是一个全连接层嘛,nn模块中有很多个层,我们可以直接来做调用)'''#写一个前向传播函数def forward(self,x):out=self.linear(x)#在线性回归中,走法直接,直接走一个全连接层,把x输入进去,得到输出结果就完事了,对于线性回归就是wx+breturn out#在自己定义的这个类当中, 我们自己去写一个模型,最基本的情况下我们写两个就足够了,
#第一个:就是构造函数当中,我们去写你用到了哪个层(比如有全连接层、池化层、卷积层等),你用到哪个层了你就在
#构造函数当中全指定出来.
#第二个:然后接下来我写一个前向传播,前向传播的意思就是我们不是用到了这么多个层嘛,那这些层你是怎么去用的,
#需要把这些数据由输入开始经过了哪些层,有输出结果,这条线穿起来,#构建model
input_dim=1
output_dim=1#输入输出维度分别都是1
model=LinearRegressionModel(input_dim,output_dim)
model#打印model(按照网络从前到后怎么走的,把你刚才设计的流程打印出来)这个当中就是一个全连接层#训练
"""
1、指定训练的次数;这里按照batch去做,一个batch就是全部数据,所以说一共迭代1000次(1000个epochs)
2、学习率;
3、指定优化器;这里使用SGD,在SGD中要告诉我优化什么东西,把模型当中涉及到的模型参数全部加进去,
一会去优化这些参数就可以了,再告诉我当前的学习率是多少。
4、定一个损失函数;损失函数是看任务去说的,一般分类任务就是交叉熵,回归任务常规条件下就是MSE损失函数
(算一下预测值和真实值之间的均方误差就完事了)"""
epochs=1000
learning_rate=0.01
optimizer=torch.optim.SGD(model.parameters(),lr=learning_rate)
criterion=nn.MSELoss()#训练
for epoch in range(epochs):#迭代1000次epoch+=1#注意转换成tensorinputs=torch.from_numpy(x_train)#开始定义的x和y是ndarray格式,不能直接进行训练labels=torch.from_numpy(y_train)#梯度要清零每一次迭代(清零相当于在上一次的结果在这一次我都不需要去做了)optimizer.zero_grad()#不清零的话每一次进行反向传播梯度都累加了#前向传播outputs=model(inputs)#刚才构建了一个model,model里边有一个前向传播,model里边我把实际的x传进去,他就是前向传播的结果#计算损失loss=criterion(outputs,labels)#现在手里有一个输出结果,还有一个标签,就可以计算损失函数#反向传播loss.backward()#计算完损失值再做一个反向传播#(注意:做完反向传播之后,相当于他是把你的梯度给你求出来了,但是没有给你进行更新,#各个需要求梯度的参数全部给你求出来了,但是此时没有做更新,更新操作需要自己来指定)#更新权重参数optimizer.step()#这个就是进行一次参数的更新,参数更新的时候他会基于你的学习率以及计算出来#的梯度值自动的帮你完成这样反向传播的一个流程if epoch % 50 == 0:print('epoch{},loss{}'.format(epoch,loss.item()))predicted=model(torch.from_numpy(x_train).requires_grad_()).data.numpy()#模型测试很简单有理数据之后,前向传播走一次就完事了
predicted#.data.numpy()表示把这个结果转化成numpy的格式,打印的就是ndarray的格式(因为后续画图有的地方需要传输ndarray的格式)#保存模型
torch.save(model.state_dict(),'model.pkl')#保存模型实际上保存的是字典的文件,model.state_dict()就是模型的权重参数,
#把w和b保存下来,叫做model.pkl
#后边还可以动态的保存模型,边训练边测试,保存那些好的模型,不好的就不要model.load_state_dict(torch.load('model.pkl'))#读取一下当前模型的权重参数,把当前的pkl读进来就行了4.2.1、GPU训练版本
PS:使用GPU进行训练,只需要把数据和模型传入到cuda里面就可以了。
我们之前的数据和模型都是传到CPU中去跑的,但是使用GPU进行训练我们要传到GPU去跑了,传入到cuda中去跑了。


下面是GPU训练版本的代码 :
import torch
import torch.nn as nn
import numpy as npclass LinearRegressionModel(nn.Module):def __init__(self,imput_dim,output_dim):super(LinearRegressionModel,self).__init__()self.linear=nn.Linear(input_dim,output_dim)def forward(self,x):out=self.linear(x)return outinput_dim=1
output_dim=1model=LinearRegressionModel(input_dim,output_dim)device=torch.device("cuda:0"if torch.cuda.is_available() else "cpu")
#这里指定设备是cuda,做个判断当前cuda是否配置好了,如果说配置好了用cuda去跑,如果说没配置好咱用cpu去跑
#---------------第一个:把模型构建好传入到cuda当中
model.to(device)#把模型.to放到哪,如果配置好了GPU那就是放到了GPU,如果没有配置好那就是CPU。criterion=nn.MSELoss()learning_rate=0.01
optimizer=torch.optim.SGD(model.parameters(),lr=learning_rate)epochs=1000
for epoch in range(epochs):#迭代1000次epoch+=1#-------------第二个:输入.to全部的传入到GPU当中inputs=torch.from_numpy(x_train).to(device)labels=torch.from_numpy(y_train).to(device)optimizer.zero_grad()outputs=model(inputs)loss=criterion(outputs,labels)loss.backward()optimizer.step()if epoch % 50 == 0:print('epoch{},loss{}'.format(epoch,loss.item()))
5、常见tensor格式
我们现在拿到的一切数据放到pytorch当中都转成一个tensor的格式,这些tensor的格式不是都一样的,还是有一定的区别:
(1)0:scalar(一个数值)
(2)1:vector(一个向量,一维)
(3)2:matrix(一个矩阵,二维)
(4)3:n-dimensional tensor(高维数据)


具体实现:




6、Pytorch中非常强大的模块:hub模块
Q1:hub模块做一些什么事?
A1:我们在看一些论文,或者资料的时候会经常听说一些词叫做model zoo,意思就是我们现在学术界有很多优秀的论文,这些优秀的论文在做各种各样的事,有做分割,有做检测的等等,model zoo就是说我把人家做的比较好的论文当中的网络模型可以拿过来,以及把他们预训练好的模型也拿过来,方便我们自己调用,说白了就是说调用人家训练好的网络架构以及训练好的权重参数,使得我们这个任务一行代码就可以解决掉(一行代码就可以把你想用的模型加载进来),这个就是model zoo或者hub模块所做的事情,方便大家进行调用。
这就是pytorch当中类似model zoo的hub模块。
6.1、Pytorch hub模块官网:
PyTorch Hub | PyTorch

6.2、使用演示
以第一个为例(3D ResNet)演示一下怎么使用:
第一步:点击第一个如下

第二步:点击Open on Google Colab
一个是在github上我们可以打开看一下他的介绍;一个是在Google当中他给你提供了一个实验环境,比如说点开一下Google那个,会到如下界面:

就是Google给你提供好了实验环境,相当于云端的实验环境;在这个实验环境当中你直接使用人家的GPU去跑就可以了。
第三步:运行单元格(首次运行需要配置)


配置GPU保存一下:

第四步:依次执行单元格
-----------------总之,就是给我们提供了一个刻意练习的环境-------------------
6.2、Pytorch hub 的github 站点:
GitHub - pytorch/hub: Submission to https://pytorch.org/hub/
6.3、演示
(下边这些代码,都是可以直接从github那个链接你选择的模型进行代码复制的)
第一步:下载人家的架构和模型,会把deeplabv3_resnet101这个网络架构下载下来,以及模型文件。

第二步:打包为list看一下有哪些可以使用(pytorch当中你选择当前的一个版本)
因为hub模块也是不停在升级的,版本升高之后,List里边打印的结果就是不同的。

第三步:下载一张实际的输入数据

第四步:调用模型

把数据进行基本的预处理,然后输入到网络当中,就可以得到最后的结果。

PS:因为别人已经把所有的工作都做完了,所以我们做起来就简单多了。







