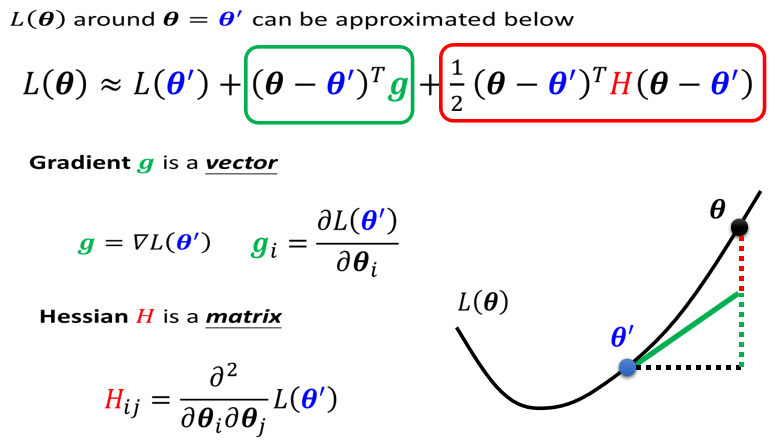
Gradient Descent梯度下降
实际上你要用一个Gradient Descent的方法来train一个neural network的话你应该要怎么做?
到底实际上在train neural network的时候Back propagation这个algorithm到底是怎么运作的?这个Back propagation是怎么样 neural network training比较有效率的?
---------------------------------------------------------------------------------------------
Gradient Descent这个方法就是:假设你的network有一大堆参数,一堆w一堆b,先选择一个初始的参数然后计算这个
对你的loss function的Gradient即
,也就是计算每一个network里边的参数
等等对你的
的偏微分,

是初始化的。
计算出这个东西以后,这个Gradient其实是一个vector,计算出这个vector以后,你就可以去更新你的参数,

是更新出来的。
然后这个process就继续的持续下去,再算一遍的gradient,然后
减掉gradient即update成
,依次计算:

在neural network里边当你用Gradient Descent方法的时候,跟我们在做Logistic Regression还有Linear Regression等等没有太大差别,但是最大的问题是在neural network里面,我们有非常多的参数,所以下面的vector是非常长的,
 这可能是一个上百万维度的vector,
这可能是一个上百万维度的vector,
所以现在最大的问题是你要如何有效的把这个百万维的vectot有效的把它计算出来,那么这个时候就是Back propagation在做的事情;所以Back propagation并不是一个和Gradient Descent不同的training的方法,他就是Gradient Descent,他只是一个比较有效的演算法,让你在计算这个gradient,这个vector的时候是可以比较有效率的把这个vector计算出来;
在使用Back propagation没有特别高深的数学,唯一需要知道的就是Chain Rule;

------------------------------------------------------------------------------------------
前向传递输入信号直至输出产生误差,反向传播误差信息更新权重矩阵。其根本就是求偏导以及高数中的链式法则;
梯度下降与反向传播
梯度下降 是 找损失函数极小值的一种方法,
反向传播 是 求解梯度的一种方法。
关于损失函数:
在训练阶段,深度神经网络经过前向传播之后,得到的预测值与先前给出真实值之间存在差距。我们可以使用损失函数来体现这种差距。损失函数的作用可以理解为:当前向传播得到的预测值与真实值接近时,取较小值。反之取值增大。并且,损失函数应是以参数(w 权重, b 偏置)为自变量的函数。
训练神经网络,“训练”的含义:
它是指通过输入大量训练数据,使得神经网络中的各参数(w 权重, b 偏置)不断调整“学习”到一个合适的值。使得损失函数最小。
如何训练?
采用 梯度下降Gradient Descent 的方式,一点点地调整参数,找损失函数的极小值(最小值)
为啥用梯度下降?
由浅入深,我们最容易想到的调整参数(权重和偏置)是穷举。即取遍参数的所有可能取值,比较在不同取值情况下得到的损失函数的值,即可得到使损失函数取值最小时的参数值。然而这种方法显然是不可取的。因为在深度神经网络中,参数的数量是一个可怕的数字,动辄上万,十几万。并且,其取值有时是十分灵活的,甚至精确到小数点后若干位。若使用穷举法,将会造成一个几乎不可能实现的计算量。
第二个想到的方法就是微分求导。通过将损失函数进行全微分,取全微分方程为零或较小的点,即可得到理想参数。(补充:损失函数取下凸函数,才能使得此方法可行。现实中选取的各种损失函数大多也正是如此。)可面对神经网络中庞大的参数总量,纯数学方法几乎是不可能直接得到微分零点的。
因此我们使用了梯度下降法。既然无法直接获得该点,那么我们就想要一步一步逼近该点。一个常见的形象理解是,爬山时一步一步朝着坡度最陡的山坡往下,即可到达山谷最底部。(至于为何不能闪现到谷底,原因是参数数量庞大,表达式复杂,无法直接计算)我们都知道,向量场的梯度指向的方向是其函数值上升最快的方向,也即其反方向是下降最快的方向。计算梯度的方式就是求偏导。
这里需要引入一个步长的概念。个人理解是:此梯度对参数当前一轮学习的影响程度。步长越大,此梯度影响越大。若以平面直角坐标系中的函数举例,若初始参数x=10,步长为1 。那么参数需要调整十次才能到达谷底。若步长为5,则只需2次。若为步长为11,则永远无法到达真正的谷底。
深度学习笔记三:反向传播(backpropagation)算法_谢小小XH-CSDN博客_backpropagati





![[vb+mo] visual baisc 6.0 基于mapobjects 2.4 开发的数字化校园电子地图](https://pic002.cnblogs.com/img/sunliming/201005/2010052714565356.jpg)