文章目录
- 局部加权线性回归
- 预测鲍鱼年龄
局部加权线性回归
具体理论见上次笔记《线性回归》
预测鲍鱼年龄
import numpy as npclass LocalWeightedLinearRegression(object):def __init__(self,train_data,train_result):""":param train_data: 输入训练数据:param train_result: 训练数据真实结果"""# 获得输入数据集的形状row, col = np.shape(train_data)# 构造输入数据数组self.Train_Data = [0] * row# 给每组输入数据增添常数项1for (index, data) in enumerate(train_data):Data = [1.0]# 把每组data拓展到Data内,即把每组data的每一维数据依次添加到DataData.extend(list(data))self.Train_Data[index] = Dataself.Train_Data = np.array(self.Train_Data)# 构造输入数据对应的结果self.Train_Result = train_result# 定义数据权重self.weight = np.zeros((row,row))# 定义局部加权回归模型参数self.Theta = []def Gaussian_Weight(self,data,k):"""这是计算测试权重的函数:param data: 输入数据:param k: 带宽系数"""# data的数据类型是np.array,那么利用dot方法# 进行矩阵运算的结果是矩阵,哪怕只有一个元素sum = np.sum(data*data)return np.exp(sum/(-2.0*k**2))def predict_NormalEquation(self,test_data,k):"""这是利用正规方程对测试数据集的局部加权线性回归预测函数:param test_data: 测试数据集:param k: 带宽系数"""# 对测试数据集全加入一维1,以适应矩阵乘法data = []for test in test_data:# 对测试数据加入1维特征,以适应矩阵乘法tmp = [1.0]tmp.extend(test)data.append(tmp)test_data = np.array(data)# 计算test_data与训练数据集之间的权重矩阵for (index, train_data) in enumerate(self.Train_Data):diff = test_data-self.Train_Data[index]self.weight[index, index] = self.Gaussian_Weight(diff, k)# 计算XTWXXTWX = self.Train_Data.T.dot(self.weight).dot(self.Train_Data)"""0.001*np.eye(np.shape(self.Train_Data.T))是防止出现原始XT的行列式为0,即防止原始XT不可逆"""# 获得输入数据数组形状row, col = np.shape(self.Train_Data)# 若XTWX的行列式为0,即XTWX不可逆,对XTWX进行数学处理if np.linalg.det(XTWX) == 0.0:XTWX = XTWX + 0.001 * np.eye(col, col)# 计算矩阵的逆inv = np.linalg.inv(XTWX)# 计算模型参数ThethaXTWY = self.Train_Data.T.dot(self.weight).dot(np.reshape(self.Train_Result,(len(self.Train_Result),1)))self.Theta = inv.dot(XTWY)# 对测试数据test_data进行预测predict_result = test_data.dot(self.Theta).T[0]return predict_resultimport LocalWeightedLinearRegression as LWLR
from sklearn.model_selection import train_test_split
import matplotlib as mpl
import matplotlib.pyplot as plt
import pandas as pd
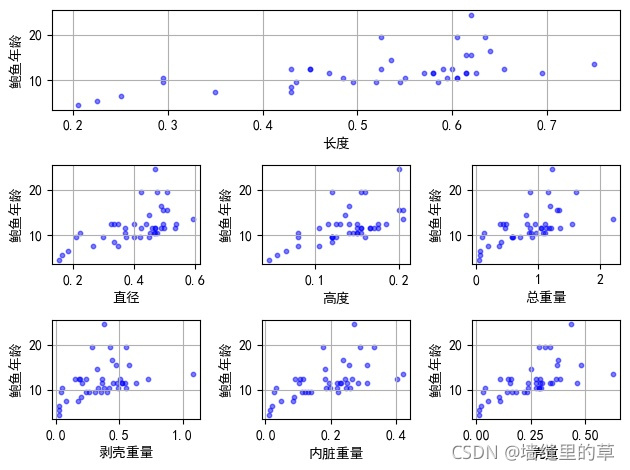
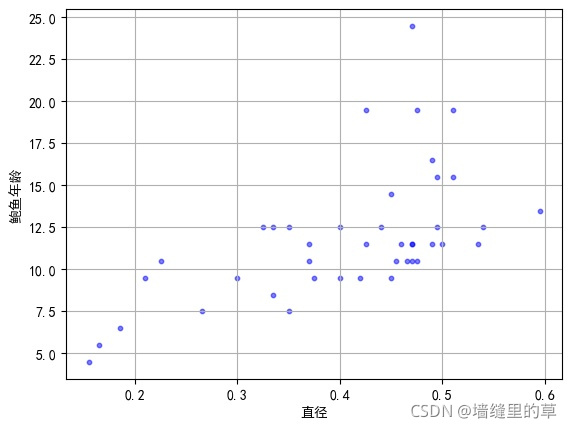
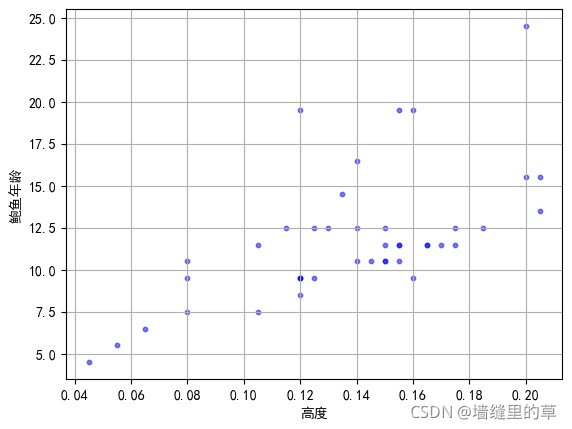
import numpy as npdef Load_Abalone(path):"""这是导入鲍鱼数据集的函数:param path: 文件路径"""# 定义鲍鱼数据和结果数组data = []result = []# 打开路径为path的文件with open(path) as f:# 遍历文件中的每一行for line in f.readlines():str = line.strip().split(',')tmp = []length = len(str[1:])# 鲍鱼数据集中的第一个属性是性别,该属性属于离散数据# 因此导入数据时必须抛开这一列,最后一列是环数,加1.5可以预测年龄for (index,s) in enumerate(str[1:]):# 最后一个数据追加到resultif index == length-1:result.append(float(s)+1.5)# 否则剩下的数据追加到tmp临时数组else:tmp.append(float(s))# 一组数据追加到数据集中data.append(tmp)data = np.array(data)result = np.array(result)return data,resultdef Merge(data,col):"""这是生成DataFrame数据的函数:param data:输入数据:param col:列名称数组"""Data = np.array(data).Treturn pd.DataFrame(Data,columns=col)def run_main():"""这是主函数"""# 导入鲍鱼数据集path = "./abalone_data.txt"Data,Result = Load_Abalone(path)# 把数据集分成训练集合测试集Train_Data,Test_Data,Train_Result,Test_Result = train_test_split\(Data,Result,test_size=0.01,random_state=10)# 解决Matplotlib中的中文乱码问题,以便于后面实验结果可视化mpl.rcParams['font.sans-serif'] = [u'simHei']mpl.rcParams['axes.unicode_minus'] = False# 可视化测试集col = ['长度','直径','高度','总重量','剥壳重量','内脏重量','壳重']# 遍历局部加权线性回归算法的预测结果fig = plt.figure()for (index, c) in enumerate(col):if index == 0:ax = fig.add_subplot(311)else:ax = fig.add_subplot(334+index-1)ax.scatter(Test_Data[:,index], Test_Result, alpha=0.5, c='b', s=10)ax.grid(True)plt.xlabel(c)plt.ylabel("鲍鱼年龄")# 子图之间使用紧致布局plt.tight_layout()plt.savefig("./测试结果可视化.jpg", bbox_inches='tight')plt.close()for (index,c) in enumerate(col):plt.scatter(Test_Data[:,index],Test_Result,alpha=0.5,c='b',s=10)plt.grid(True)plt.xlabel(c)plt.ylabel("鲍鱼年龄")plt.savefig("./"+c+"可视化.jpg",bbox_inches='tight')#plt.show()plt.close()# 初始化局部加权线性回归模型lwlr = LWLR(Train_Data,Train_Result)# 初始化局部加权回归带宽系数参数K = [0.0001,0.001,0.003,0.005,0.01,0.05,0.1,0.3,0.5]tmp = list(np.arange(1,101))K.extend(tmp)predict_result = []Loss = []# 把测试集进行从小到大排序sort = np.argsort(Test_Data[:, 1])Test_Data = Test_Data[sort]Test_Result = Test_Result[sort]# 遍历每个带宽系数,利用局部加权线性回归算法进行预测,并计算预测误差for k in K:# 在带宽系数k下,利用局部加权线性回归进行预测predict = lwlr.predict_NormalEquation(Test_Data,k)#print(np.shape(predict))# 计算每组数据的预测误差loss = (Test_Result-predict)**2print("k=%f时的误差:%f"%(k,np.sum(loss)))predict_result.append(predict)Loss.append(loss)# 可视化预测结果plt.scatter(Test_Data[:, 1], Test_Result, alpha=0.5, c='b', s=10)plt.plot(Test_Data[:,1],predict,'r')plt.grid(True)plt.xlabel('直径')plt.ylabel("鲍鱼年龄")plt.savefig("./k=" + str(k) + "可视化.jpg", bbox_inches='tight')plt.close()# 部分预测结果可视化# k = [0.1,0.3,1,3,10,100]k = [0.1,0.3,1,3,10,100]index= [6,7,9,11,18,108]# 遍历每个带宽系数,利用局部加权线性回归算法进行预测,并计算预测误差fig = plt.figure()for (j,(i,k_)) in enumerate(zip(index,k)):# 在带宽系数k下,利用局部加权线性回归进行预测predict = predict_result[i]# 可视化预测结果ax = fig.add_subplot(230+j+1)ax.scatter(Test_Data[:, 1], Test_Result, alpha=0.5, c='b', s=10)ax.plot(Test_Data[:,1],predict,'r')ax.grid(True)ax.legend(labels=["k=" + str(k_)], loc="best")plt.xlabel('直径')plt.ylabel("鲍鱼年龄")plt.tight_layout()plt.savefig("./部分预测结果.jpg")# 保存预测数据data = [Test_Result]col = ["真实结果"]for (index,k) in enumerate(K):data.append(predict_result[index])col.append("k="+str(k))Data = Merge(data,col)Data.to_excel("./真实结果与预测结果.xlsx")# 保存预测误差结果及其统计信息data = []col = []for (index, k) in enumerate(K):data.append(Loss[index])col.append("k=" + str(k))Data = Merge(data,col)Data.to_excel("./预测误差.xlsx")information = Data.describe()information.to_excel("./预测误差统计信息.xlsx")# 可视化不同带宽参数的局部加权线性回归模型在测试集的均方误差和预测标准差K = list(np.arange(1, 101))col = ["LWLR-MSE", "LWLR-std"]LWLR_MSE = list(information.loc['mean'])[9:]LWLR_std = list(information.loc['std'])[9:]plt.plot(K, LWLR_MSE, 'b')plt.plot(K, LWLR_std, 'c-.')plt.grid(True)plt.legend(labels=col, loc='best')plt.xlabel("带宽系数")plt.savefig("./局部加权线性回归的预测均方误差和标准差.jpg", bbox_inches='tight')plt.show()plt.close()if __name__ == '__main__':run_main()